Retrieval-Augmented Generation(RAG) - Part 1
Today Keys : rag, retrieval, augmented, generation, llm, vector, chunk, prompt, langchain, hallucination, mydata
이번 포스팅에서는 사용자의 질문에 대해서 LLM에서 추가 학습 없이 내부 데이터를 이용하여 답변을 생성하여, LLM의 환각(Hallucination)을 줄이는 데 유용한 RAG(Retrieval-Augmented Generation) 아키텍처에 대한 첫 번 째 포스팅입니다. 이번 포스팅에서는 Azure OpenAI와 Cognitive Search를 이용해서 간단한 RAG 아키텍처를 만들어 봅니다.
각 섹션에 사용된 코드는 해당 섹션 하단에 링크에서 확인 가능합니다.
첫 번째 포스팅에서는 기본적인 환경을 구성하고, 사용자가 넣은 데이터에 대한 답변을 생성하는 예시에 대해서 알아봅니다.
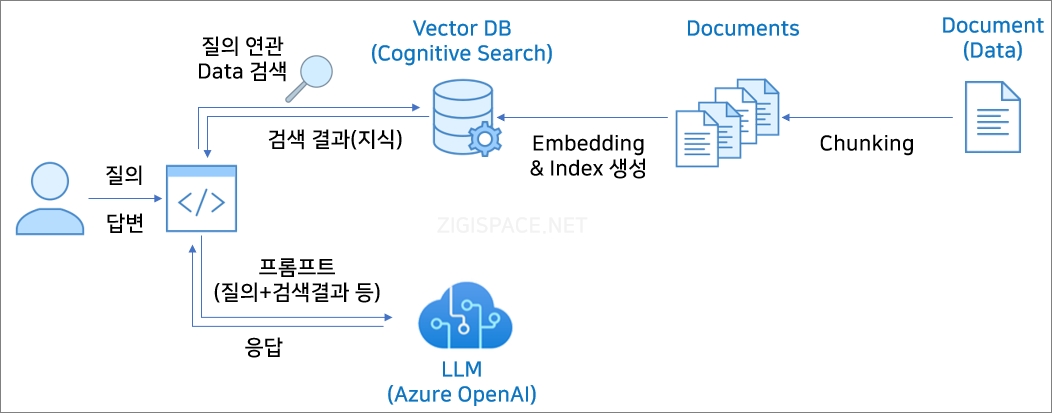
다음은 포스팅에서 진행하게 될 전체적인 구성과 Flow 입니다.

먼저 Data(Documents)를 나누고(Chunking), Embedding 하여, Cognitive Search로 올립니다.
사용자가 질의를 하면, 질의 내용과 관련된 Data를 Cognitive Search에서 검색하여 얻은 결과 Data와 질의 내용을 포함하여 프롬프트를 작성하여, LLM에 요청하여, 답변 내용을 응답을 받게 됩니다.
그럼 이제부터 단계 별로 진행 해보겠습니다.
Cognitive Search 만들기
개인 Data에 대한 벡터 검색을 하기 위해서 Azure AI Service 중에 하나인 'Cognitive search' 를 사용 할 수 있습니다.
먼저 Cognitive search 서비스 메뉴로 들어가서 서비스를 만듭니다.

Cognitive Search 서비스를 만드는 과정을 단계 별로 살펴보면,
구독과 Resource Group을 설정하고, Cognitive Search 서비스 이름 지정합니다.
그리고 Cognitive Searvice의 Location과 Pricing tier를 지정합니다.
여기에서는 Standard Tier로 선택했습니다.

Pricing Tier에 따라서, Indexes와 Indexer 수나, Storage 등의 사양 등이 다르기 때문에 목적에 따라서, 원하는 Tier로 선택 할 수 있습니다. 간단한 테스트 시에는 Free Tier를 사용하셔도 됩니다.

다음은 Cognitive Search의 Scale을 조정합니다.
Pricing Tier 별로 제한 된 Search Unit 만큼의 Scale 조정이 가능합니다.
Replica의 경우 서비스 가용성에 영향을 미치기 때문에 상용 환경에서는 가용성을 고려하여 적절하게 선택해야 합니다.
Search Unit은 Replica와 Partitions의 곱으로 계산됩니다.
단, Scale에 따라서, 그만큼 비용도 증가하기 때문에 테스트 시에는 적정 Scale로만 하셔야 합니다.

다음은 Cognitive Search 서비스에 접근을 제한할 수 있는 Networking 설정입니다.
여기에서는 기본 값인 Public으로 두고 진행하지만,
실제 환경에서는 보안 목적상 Private으로 구성하여 사용하는 것을 권고합니다.

필요에 따라 Tag 설정을 합니다.
설정한 값을 확인하고, "create" 버튼을 클릭해서 Cognitive Search를 만듭니다.

잠시 후, 생성된 Cognitive Search 정보를 다음과 같이 확인 할 수 있습니다.

API를 사용해서, Cognitive Search에 Index를 넣어 줄 것이기 때문에,
Cognitive Search의 API Keys를 'setting-Keys' 메뉴에서 확인하여 복사해 둡니다.

Azure OpenAI 만들기
다음은, Azure OpenAI에 대한 설정입니다.
Azure OpenAI를 먼저 만듭니다.
구독, Resource group, Region, 서비스 이름, Pricing tier를 설정합니다.
현재 Azure OpenAI의 Pricing tier는 Standard S0 1가지만 있습니다. ('23년 9월 기준)

다음은 Azure OpenAI 서비스에 접근을 제한할 수 있는 Networking 설정입니다.
여기에서는 기본 값인 All network로 두고 진행했지만,
실제 환경에서는 보안 목적상 접근을 제한하여 구성하는 것을 추천합니다.

필요에 따라 Tag 설정을 합니다.

설정된 값을 확인하고, 'Create' 버튼을 클릭해서 Azure OpenAI를 생성합니다.
Azure OpenAI가 생성되고 나면, 아래와 같이 Azure OpenAI에 대한 정보를 확인 할 수 있습니다.

Azure OpenAI도 API를 이용해서 사용 할 예정이기 때문에
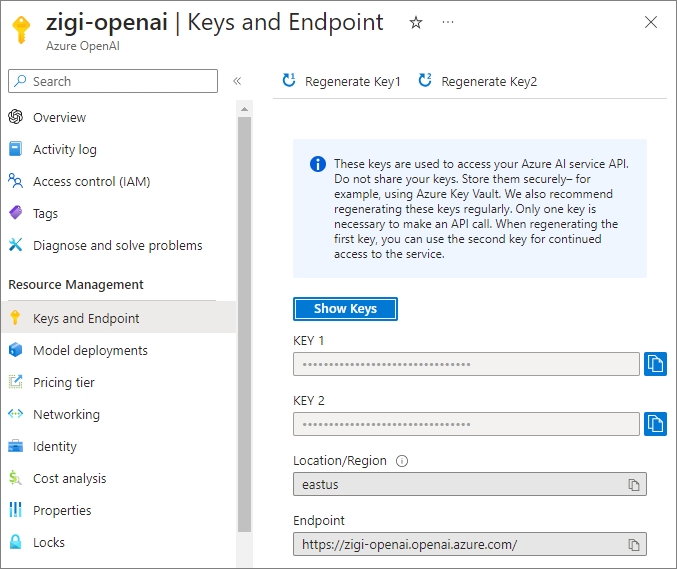
생성된 Azure OpenAI의 'Keys and Endpoint' 메뉴에서 확인하여 복사해 둡니다.
Azure OpenAI Studio에서 모델 확인 및 모델 배포
다음은 Azure OpenAI 사용을 위해서 모델을 배포합니다.
Azure OpenAI의 모델 관리는 Azure OpenAI Studio에서 하게 되는 데,
Model deployments 메뉴를 통해서 들어갈 수 있습니다.
Azure OpenAI Studio의 'Management' - 'Models' 로 가면 다음과 같이 Azure OpenAI에서 사용 가능한 모델을 확인 할 수 있습니다.
Preview로 제공되는 DALL-E를 제외하면, GPT-4, GPT-3.5, Embeddings 모델을 사용 할 수 있습니다.
단, GPT-4 모델의 경우에는 별도 Access 요청을 통해서 양식을 작성하여 제출하고 승인이 되야 사용이 가능합니다.
사용하고자 하는 모델을 선택한 이후에, 상단의 'Deploy' 메뉴를 통해서 모델을 배포합니다.

배포된 모델은 'Management' - 'Deployments' 메뉴에서 확인이 가능합니다.

Data Chunking 및 Embedding하여, Cognitive Search의 Index 생성
이제 사용자 Data를 Cognitive Search로 올리기 위한 가공 작업을 합니다.
Cognitive Search로 질의와 관련된 컨텐츠 검색 시에 Vector 검색을 하고, 검색된 데이터를 LLM에 던져야 하기 때문에 데이터를 Chunking 합니다.
참고로 제가 사용한 데이터는 'IT 엔지니어를 위한 입문' 서적의 PDF 파일입니다.
데이터를 Chunking하여 나눠진 데이터 내용에 대해서 Embedding을 하여, Cognitive Search에 Chunk Data와 Vector 정보를 이용해서 Index를 만듭니다.
Embedding을 위해서 Azure OpenAI의 text-embedding-ada-00 모델을 사용했습니다.
본 과정을 모두 Python 코드로 진행했으며, Embedding과 Index 생성과 데이터 업로드를 위해서 Azure OpenAI와 Cognitive Search를 API로 호출 했습니다.
다음은 코드를 실행한 결과입니다.


Cognitive Search에서 생성된 Index를 다음과 같이 확인 할 수 있습니다.

Index 내용을 살펴보면, ID, Source(파일명), Content(Chunk된 데이터), content_vector(Content에 대한 Vector 정보) Field가 포함되어 있는 것을 볼 수 있습니다.

>> Code : https://github.com/NetworkZIGI/ai/blob/main/Create_Index.py
사용자 질의을 Cognitive Search에서 연관 데이터를 찾아서, Azure OpenAI의 GPT 모델로 답변 받기
마지막으로, 사용자 질의 내용과 관련된 데이터를 Cognitive Search에서 Vector 검색을 통해 찾고 이 데이터를 사용자 질의와 함께 프롬프트에 넣어서 GPT에서 답변을 생성합니다.
이 과정도 마찬가지로 Python으로 Azure OpenAI와 Cognitive Search의 API를 사용하였습니다.
첫 번째 질문은 'ZIGI'가 누구야?
두 번째 질문은 'IT 엔지니어를 위한 네트워크 입문의 초판 발행일과 저자는 누구야?'
로 2개의 질문을 사용했습니다.
각각 'IT엔지니어를 위한 네트워크 입문' 서적의 저자 소개와 출판 정보를 통해서 데이터를 가져오고, 이를 LLM을 통해서 다음과 같이 자연스러운 답변 문장을 생성한 것을 볼 수 있습니다.

>> Code : https://github.com/NetworkZIGI/ai/blob/main/zigi-qa.py