AWS Bedrock - Part 3
Today Keys : bedrock, rag, retrieval, augmented, generative, ai, 생성, foundation model, claude, anthorpic, model
이번 포스팅은 지난 9월 28일에 GA에 된 Amazon Bedrock에 대한 세 번째 포스팅입니다.
Amazon Bedrock은 FM(기본 모델)을 사용하여 생성 AI 애플리케이션을 구축하고 확장 할 수 있도록 도와주며, AI21 Labs/ Anthropic/Cohere/Meta/Stability AI 및 Amazon을 포함한 주요 AI 회사의 고성능 FM 선택과 함께 생성 AI를 구축하는 데 필요한 광범위한 기능 세트를 제공하는 완전관리형 서비스입니다.
세 번째 포스팅에서는 Amazon Bedrock을 활용하기 위해 제공되는 QuestionAnswering에 대한 예시 코드를 알아봅니다.
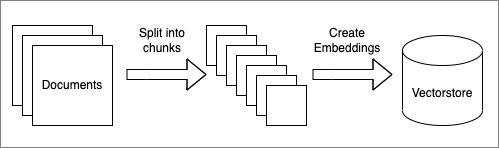
Question Answering에 대한 예시는 사용자의 질문에 대해서 LLM에서 추가 학습 없이 내부 데이터를 이용하여 답변을 생성하여, LLM의 환각(Hallucination)을 줄이는 데 유용한 RAG(Retrieval-Augmented Generation) 아키텍처를 사용합니다.
예시 코드는 Amazon Bedrock Workshop을 위한 Github에서 제공되는 코드를 일부 변경하여 실행하였습니다.
Code 2-1. Question Answering - 문서 Chunking 및 Vector DB 생성
__import__('pysqlite3')
import sys
sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')
import os
from langchain import LLMChain, OpenAI, PromptTemplate
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
import os
from utils import bedrock
from langchain.embeddings import BedrockEmbeddings
os.environ["AWS_DEFAULT_REGION"] = "us-east-1"
os.environ["AWS_PROFILE"] = "zigi-bedrock"
boto3_bedrock = bedrock.get_bedrock_client(
# IAM User에 Bedrock에 대한 권한이 없이 Role을 Assume하는 경우
# assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None),
region=os.environ.get("AWS_DEFAULT_REGION", None)
)
#Embedding 모델 정의
bedrock_embeddings = BedrockEmbeddings(client=boto3_bedrock, model_id="amazon.titan-embed-text-v1")
pdf_files = [
"./data/visa-kor.pdf",
"./data/card.pdf",
"./data/network.pdf"
]
# Chunking을 위한 Text Splitter 설정 : Spiltter
text_splitter = CharacterTextSplitter(chunk_size=3000, chunk_overlap=600)
texts = []
#문서 Chunking
for pdf_file in pdf_files:
loader = PyPDFLoader(pdf_file)
documents = loader.load()
texts.extend(text_splitter.split_documents(documents))
#벡터 DB 생성
docsearch = Chroma.from_documents(texts, bedrock_embeddings,persist_directory="./zigi_chromadb")
print("Vector DB에 데이터를 저장 완료했습니다")
Code 2-2. Question Answering - 질의에 대한 내용을 Vector DB 조회 후, 결과 값과 질의 내용을 LLM을 질의 및 답변
__import__('pysqlite3')
import sys
sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')
import os
from utils import bedrock
from langchain.embeddings import BedrockEmbeddings
from langchain.llms.bedrock import Bedrock
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
os.environ["AWS_DEFAULT_REGION"] = "us-east-1"
os.environ["AWS_PROFILE"] = "zigi-bedrock"
boto3_bedrock = bedrock.get_bedrock_client(
# IAM User에 Bedrock에 대한 권한이 없이 Role을 Assume하는 경우
# assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None),
region=os.environ.get("AWS_DEFAULT_REGION", None)
)
# LLM 모델 객체 생성
llm = Bedrock(
model_id="anthropic.claude-v2", client=boto3_bedrock, model_kwargs={"max_tokens_to_sample": 1000}
)
# Embedding 모델 객체 생성
bedrock_embeddings = BedrockEmbeddings(client=boto3_bedrock, model_id="amazon.titan-embed-text-v1")
# 벡터 DB 설정 및 벡터 Search를 위한 Embedding 객체 설정
docsearch = Chroma(persist_directory="./zigi_chromadb", embedding_function=bedrock_embeddings)
# 프롬프트 정의
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer in Korean:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
# QA를 위한 Chain 설정
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type='stuff',
retriever=docsearch.as_retriever(search_kwargs={'k': 3 }),
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
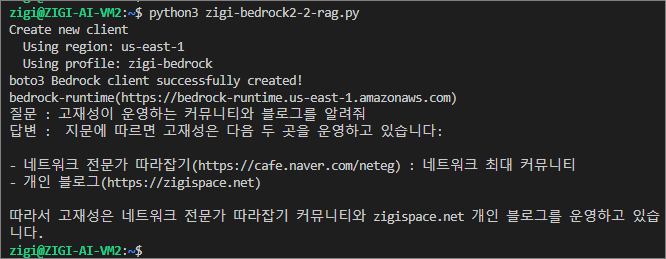
query = "고재성이 운영하는 커뮤니티와 블로그를 알려줘"
result = qa({"query": query})
answer = result['result']
print(f"질문 : {query}")
print(f"답변 : {answer}")
Bedrock을 활용한 RAG 구현에 대한 실행 결과 값 예시 1.

Bedrock을 활용한 RAG 구현에 대한 실행 결과 값 예시 2.