 Apstra - IBN Solution
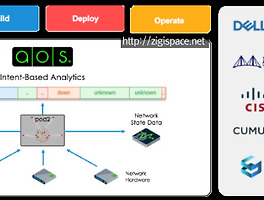
Today Keys : IBN, Intent, Apstra, 인텐트, 의도, 기반, 네트워크, Network, 앱스트라, AOS 이번 포스팅은 IBN(Intent-Based Networking) 솔루션인 Apstra에 대한 화면 간단한 소개입니다. Apstra는 Apstra Operating System(AOS)를 이용하여, 다양한 벤더(운영체제)의 네트워크 장비를 관리할 수 있는 솔루션이라고 볼 수 있습니다. 현재 지원되는 벤더 뿐만 아니라 지원되는 벤더와 OS는 지속적으로 늘어나고 있다고 합니다.Template 형태의 사용자 의도의 설정을 벤더에 종속되지 않게 네트워크 장비에 deploy 합니다. 해당 설정은 AOS에서 지속적으로 관리되면서, 최초의 의도와 벗어난 변경이 발생될 경우에 이를 알려주고 ..
Apstra - IBN Solution
Today Keys : IBN, Intent, Apstra, 인텐트, 의도, 기반, 네트워크, Network, 앱스트라, AOS 이번 포스팅은 IBN(Intent-Based Networking) 솔루션인 Apstra에 대한 화면 간단한 소개입니다. Apstra는 Apstra Operating System(AOS)를 이용하여, 다양한 벤더(운영체제)의 네트워크 장비를 관리할 수 있는 솔루션이라고 볼 수 있습니다. 현재 지원되는 벤더 뿐만 아니라 지원되는 벤더와 OS는 지속적으로 늘어나고 있다고 합니다.Template 형태의 사용자 의도의 설정을 벤더에 종속되지 않게 네트워크 장비에 deploy 합니다. 해당 설정은 AOS에서 지속적으로 관리되면서, 최초의 의도와 벗어난 변경이 발생될 경우에 이를 알려주고 ..


