
- 추가한 File 내용을 검색하여, Assistant가 답변을 할 수 있도록 함. (RAG를 서비스화)
▪ Vector Store 별로 최대 10,000 파일 지원
▪현재 Preview로 지원(현재 File Search에 대한 비용 무료)
File Search 동작 원리
▪ API 지원 버전 2024-05-01-preview
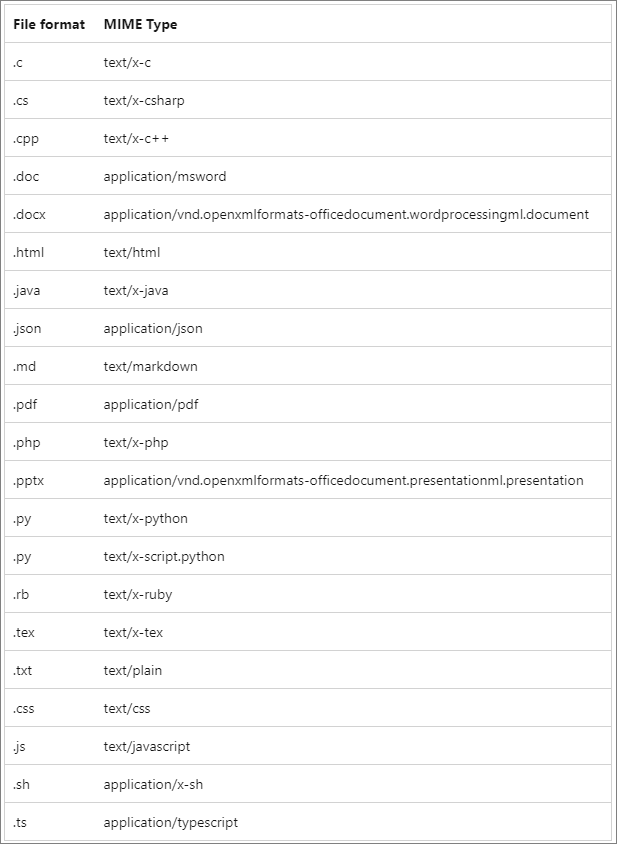
지원 파일 형식
Azure OpenAI Assistants File Search 사용해 해보기 (Preview)
본 예제에서는 여행 가이드 문서를 기반으로 답변을 할 수 있는 여행 가이드 도우미를 생성합니다.
Assistant 이름을 '여행 가이드 도우미'로 하고,
Instructions를 여행 가이드에 맞는 역할을 정의 해줍니다.
마지막으로 Assistant 생성 시, Assistant에서 사용 가능한 Tool로 File_search를 추가합니다.
from openai import AzureOpenAI
import time
import json
import os
client = AzureOpenAI(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview",
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT")
)
assistant = client.beta.assistants.create(
name="여행 가이드 도우미",
instructions="당신은 여행 가이드 전문가입니다. 지식 기반을 사용하여 여행에 필요한 정보 질문에 대해서 알려주세요.",
model="gpt-4o",
tools=[{"type": "file_search"}],
)
다음은 여행 가이드 파일을 저장 할 Vector Store를 만들어 줍니다.
여기에서는 특정 파일을 직접 지정해서, 업로드를 하고 있지만
특정 디렉토리를 읽어서 디렉토리의 모든 파일을 불러오는 방법 등을 이용해서
다수의 파일을 Vector Store에 올릴 수도 있습니다.
파일은 파리와 대만 여행 가이드 pdf를 사용했습니다.
vector_store = client.beta.vector_stores.create(name="여행 가이드")
file_paths = ["/content/파리.pdf", "/content/대만.pdf"]
file_streams = [open(path, "rb") for path in file_paths]
file_batch = client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id, files=file_streams
)
print(file_batch.status)
print(file_batch.file_counts)
File 업로드의 Status와 File counts를 출력하면 다음과 같이
2개의 파일이 정상적으로 올라갔다는 것을 결과 값이 나오는 것을 확인 할 수 있습니다.

앞서 생성한 Vector Store의 ID 값으로 Assistant가 File Search에 사용 할 Vector Store로 연결해 줍니다.
assistant = client.beta.assistants.update(
assistant_id=assistant.id,
tool_resources={"file_search": {"vector_store_ids": [vector_store.id]}},
Thread를 만들고, Message를 생성 후 Thread를 실행합니다.
User 메시지로는 '에뻬르네'라는 도시의 샴페인 하우스에 대한 정보를 알아보기 위해서
'에뻬르네의 샴페인 하우스 정보를 알려줘'
로 지정했습니다.
Assistant는 File Search 도구를 사용 할 수 있도록 지정해놨고, 질문 내용이 여행에 대한 정보 질문이기 때문에
Vector Store에 해당 질문과 관련된 Chunk를 검색하고, 해당 검색 결과를 토대로 답변을 생성하게 됩니다.
마지막으로 생성한 답변을 출력합니다.
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="이스탄불 뮤지엄패스가 뭐야?",
)
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
status = run.status
while status not in ["completed", "cancelled", "expired", "failed"]:
time.sleep(5)
run = client.beta.threads.runs.retrieve(thread_id=thread.id,run_id=run.id)
status = run.status
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
result = messages.model_dump_json()
result_dict = json.loads(result)
print(result_dict["data"][0]["content"][0]["text"]["value"])
출력된 답변의 내용을 확인하기 전에,
'파일.pdf'에 있는 문서 내용을 잠시 살펴 보겠습니다.
우측에 녹색 박스로 표기 해놓은 부분이 사용자의 질의에 답변을 하기 위해 필요한 영역입니다.
2개의 샴페인 하우스에 대한 정보가 있는 것을 볼 수 있습니다.

앞선 코드의 출력 값을 확인해 보면, 아래와 같이 '파리.pdf'의 파일 내용을 참조하여 답변 한 것을 볼 수 있습니다.

다만 마지막 줄의 경우에는 앞선 보여드린 문서에서는 보이지 않는 부분인데,
'파리.pdf'의 다른 영역에서 아래와 같이 마지막 줄과 관련된 부분을 확인 할 수 있습니다.
즉, 문서 내용에서 관련된 Chunk를 다수 개 검색하고, 이를 토대로 필요한 답변을 생성한 것을 볼 수 있습니다.
다만, 답변을 생성한 내용에는 '베타 거리'라고 표기 되어 있으나, 실제 하단의 원문을 보면 '강 베타 거리'인 것을 볼 수 있습니다.
이는 원본 문서에서 '강베타 거리'에서 '강' 이라는 글자가 위치상으로 떨어져 있고, 문서를 읽어서 정리하는 과정에서 '강'과 '베타 거리' 부분이 연결되어 인식되지 않았을 것을 추정 할 수 있습니다.

사실 File Search의 경우도 RAG를 사용자가 보다 쉽게 사용 할 수 있도록 할 수 있는 것이지만,
결국 원본 문서에 대해서 전처리에 따라서, 최종 LLM이 생성하는 결과 값에 대한 영향을 줄 수 있다는 것을 확인 할 수 있는 것이기도 합니다.
세부적인 부분이 조금은 아쉬울 수 있긴하지만,
전반적으로는 사용자가 직접 구현해야 하는 RAG 영역을 파일을 업로드해서 사용 할 수 있기 때문에 활용성은 굉장히 높을 것 같습니다.



